● 异常是通过抛出(throw)对象而引发的。该对象的类型决定应该激活哪个处理代码。被选中的处理代码是调用链中与该对象类型匹配且离抛出异常位置最近的那个。
执行throw的时候,不会执行跟在throw后面的语句,而是将控制从throw转移到匹配的catch,该catch可以是同一函数中局部的catch,也可以在直接或间接调用发生异常的函数的另一个函数中。
● 栈展开
异常的传播方式和调用链相反,这称之为栈展开。在异常发生的地方,编译器必须完成以下的事情:
如果throw发生在try区块中,寻找匹配的cath语句,如果找不到,则当前函数立刻返回,并往上一级调用函数中寻找匹配的catch语句,该动作将一直重复直到有合适的catch语句出现。如果一直到最后都没有发现合适的catch语句,系统将调用terminate,而默认情况下,terminate将调用abort结束整个进程。
1.在栈展开期间,提早退出包含throw的函数和调用链中可能的其他函数。一般而言,这些函数已经创建了可以在退出函数时销毁的局部对象。因异常退出函数时,编译器保证适当地撤销局部对象。
2.析构函数应该从不抛出异常。
3.构造函数抛出异常时,也要保证将会适当销毁已经构造的成员。
● 捕获异常
1.查找匹配的处理代码
在查找匹配的catch期间,找到的catch不必是与异常最匹配的那个catch,相反,将选中第一个找到的可以处理该异常的catch。因此,在catch子句列表中,最特殊的catch必须最先出现。
2.带有因继承而相关的类型的多个catch子句,必须从最低派生类型到最高派生类型排序。
● 重新抛出
有可能当个catch不能完全处理一个异常,catch可以通过重新抛出将异常传递给函数调用链中更上层的函数。throw;
● 函数测试块
为了处理来自构造函数初始化的异常,必须将构造函数编写为函数测试块。可以使用函数测试块将一组catch子句与函数联成一个整体。
template <class T> Handle<T>::Handle(T *p)
try : ptr(p), use(new size_t(1)){
//…empty
}catch(const std::bad_alloc &e){
handle_out_of_memory(e);
}
●异常类层次

●auto_ptr类
头文件memory中定义

auto_ptr只能用于管理从new返回的一个对象,他不能管理动态分配的数组。
正如我们所见,当auto_ptr被复制或复制的时候,有不寻常的行为,因此,不能将auto_ptr存储在标准库容器类型中。
1.为异常安全的内存分配使用auto_ptr
如果通过常规指针分配内存,而且在执行delete之前发生异常,就不会自动释放该内存。
如果使用一个auto_ptr对象来代替,将会自动释放内存,即使提早退出这个块也是这样。
2.auto_ptr是可以保存任何类型指针的模板
auto_ptr<string> ap(new string(“str”));
3.将auto_ptr绑定到指针
在最常见的情况下,将auto_ptr对象初始化为由new表达式返回的对象的地址。
auto_ptr<int> pi(new int(1024));
接受指针的构造函数为explicit构造函数,所以必须使用初始化的直接形式来创建auto_ptr对象:
auto_ptr<int> pi = new int(1024); //error!!!
pi所指向的由new表达式创建的对象在超出作用域时自动删除。就算发生异常。
4.使用auto_ptr对象
auto_ptr类定义了解引用操作符(*)和箭头操作符(->)的重载版本。
auto_ptr<string> ap(new string(“str”));
*ap = “TRex”;
string s = *ap;
ap->empty();
5.auto_ptr对象的复制和赋值是破坏性操作
在复制或者赋值auto_ptr对象之后,原来的auto_ptr对象不指向对象而新的auto_ptr对象拥有基础对象。
auto_ptr<string> ap1(new string(“str”));
auto_ptr<string ap2(ap1);
当复制auto_ptr对象或者对auto_ptr对象赋值的时候,右边的auto_ptr对象让出对基础对象的所有职责并重置为未绑定的auto_ptr对象。所以,删除string对象的是ap2而不是ap1,在复制之后,ap1不再指向任何对象。
6.赋值删除左操作数指向的对象
auto_ptr<string> ap3(new string(“ap3”));
ap3 = ap2;
将ap2赋值给ap3之后,删除了ap3指向的对象,将ap3置为指向ap2所指的对象,ap2是未绑定的auto_ptr对象。
7.auto_ptr的默认构造函数
如果不给定初始式,auto_ptr对象时未绑定的,他不指向对象。
8.测试auto_ptr对象
if(p_auto.get()) *p_auto = 1024;
9.reset操作。
if(p_auto.get()) *p_auto = 1024;
else p_auto.reset(new int(1024));
auto_ptr的缺陷:
(1)不要使用auto_ptr对象保存指向静态分配对象的指针。否则,当auto_ptr对象本身被撤销时,它将试图删除指向非动态分配对象的指针,导致未定义的行为。
int a=1;
auto_ptr<int> ap(&a); //编译没有问题,会导致未定义行为
(2)不要使两个auto_ptr对象指向同一对象。
auto_ptr<int> ap1(new int (1024));
auto_ptr<int> ap2(ap1.get());
(3)不要使用auto_ptr对象保存指向动态分配数组的指针。从源代码中可以看出,它用的是delete操作符,而不是delete [ ] 操作符。
(4)不要将auto_ptr对象存储在容器中。因为auto_ptr的复制和赋值具有破坏性。不满足容器要求:复制或赋值后,两个对象必须具有相同值。
●异常说明
异常说明有如下的几种形式:
1. 指定异常
T funNname( parameterlist ) throw( T1, T2,····,Tn);
其中 T 是类型, parameterlist 是参数列表, 而类型 T1, T2,····,Tn 是函数会抛出的异常。
2. 不抛出异常
T funNname( parameterlist ) throw( );
抛出异常类型列表为空,表示的是该函数不抛出任何类型异常。
3. 抛出任意类型的异常
T funNname( parameterlist );
这表示该函数可以抛出任意类型的异常。
●命名空间
1 命名空间介绍
使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突。下面是一个简单的命名空间的例子:
namespace MyNames {
int iVal1 = 100;
int iVal2 = 200;
}
2 命名空间的成员
命名空间的一个例子就是std,它是C++定义标准库的命名空间。为使用cout 流对象,你必需告诉编译器cout 已存在于std 名字空间中。为达到上述目的可以指定名字空间的名称和作用域限定操作符(::)作为cout 标识符的前缀。
using std::cout;
using声明中引入的名字遵循常规作用域规则,从using声明点开始,直到包含该using声明的作用域的末尾,名字都是可见的。
3 using namespace 语句
使用已在命名空间中定义的标识符的另一种方法是将using namespace 语句把需要使用到的命名空间包含进来。
#include <iostream>
using namespace std;
int main() {
cout << “hello”;
return 0;
}
4 嵌套命名空间
命名空间可以在其他命名空间中被定义。在这种情况下,仅仅通过使用外部的命名空间作为前缀,一个程序仅可以引用外部命名空间中定义的标识符。要想引用内部命名空间定义的标识符,需要使用外部和内部命名空间名称作为前缀。
#include <iostream>
namespace MyOutNames {
int iVal1 = 100;
int iVal2 = 200;
namespace MyInnerNames {
int iVal3 = 300;
int iVal4 = 400;
}
}
int main() {
std::cout << MyOutNames::iVal1 << std::endl;
std::cout << MyOutNames::iVal2 << std::endl;
std::cout << MyOutNames::MyInnerNames::iVal3 << std::endl;
std::cout << MyOutNames::MyInnerNames::iVal4 << std::endl;
return 0;
}
5 无名命名空间
尽管给定命名空间的名称是有益的,但你可以通过在定义中省略命名空间的名称而简单地声明无名命名字空间。
namespace {
int iVal1 = 100;
int iVal2 = 200;
}
6 命名空间的别名
可以给命名空间取别名,它是已定义的命名空间的可替换的名称。通过将别名指定给当前的命名空间的名称,你可以简单地创建一个命名空间的别名。
#include <iostream>
namespace MyNames {
int iVal1 = 100;
int iVal2 = 200;
}
namespace MyAlias = MyNames;
int main() {
std::cout << MyAlias::iVal1 << std::endl;
std::cout << MyAlias::iVal2 << std::endl;
return 0;
}
● 重载与命名空间
正如我们所见,每个命名空间维持自己的作用域,因此,作为两个不同命名空间的成员的函数不能互相重载。但是,给定命名空间可以包含一组重载函数成
员。
一般而言,命名空间内部的函数匹配(第 7.8.2 节)以与我们已经见过的方式相同的方式进行:
1. 找到候选函数集。 如果一个函数在调用时其声明可见并且与被调用函数同名,这个函数就是候选者。
2. 从候选集中选择可行函数。 如果函数的形参数目与函数调用的实参数目相同,并且每个形参都可用对应实参匹配,这个函数就是可行的。
3. 从可行集合中选择一个最佳匹配,并产生代码调用该函数。如果可行集合为空,则调用出错,没有匹配;如果可行集合非空且没有最佳匹配,则调
用有二义性。
候选函数与命名空间:
namespace NS {
class Item_base { };
void display(const Item_base&) { }
}
// Bulk_item’s base class is declared in namespace NS
class Bulk_item : public NS::Item_base { };
int main() {
Bulk_item book1;
display(book1);
return 0;
}
display 函数的实参 book1 具有类类型 Bulk_item。display 调用的候选函数不仅是在调用 display 函数的地方其声明可见的函数,还包括声明
Bulk_item 类及其基类 Item_base 的命名空间中的函数。命名空间 NS 中声明的函数 display(const Item_base&) 被加到候选函数集合中。
重载与 using 声明:
using 声明声明一个名字。没有办法编写 using 声明来引用特定函数声明:
using NS::print(int); // error: cannot specify parameter list
using NS::print; // ok: using declarations specify names only
如果命名空间内部的函数是重载的,那么,该函数名字的 using 声明声明了所有具有该名字的函数。 如果命名空间 NS 中有用于 int 和 double 的函数,
则 NS::print 的 using 声明使得两个函数都在当前作用域中可见。
重载与 using 指示:
using 指示将命名空间成员提升到外围作用域。如果命名空间函数与命名空
间所在的作用域中声明的函数同名,就将命名空间成员加到重载集合中:
namespace libs_R_us {
extern void print(int);
extern void print(double);
}
void print(const std::string &);
// using directive:
using namespace libs_R_us;
// using directive added names to the candidate set for calls to print:
// print(int) from libs_R_us
// print(double) from libs_R_us
// print(const std::string &) declared explicitly
void fooBar(int ival)
{
print(“Value: “); // calls global print(const string &)
print(ival); // calls libs_R_us::print(int)
}
跨越多个 using 指示的重载:
如果存在许多 using 指示,则来自每个命名空间的名字成为候选集合的组
成部分:
namespace AW {
int print(int);
}
namespace Primer {
double print(double);
}
// using directives:
// form an overload set of functions from different namespaces
using namespace AW;
using namespace Primer;
long double print(long double);
int main() {
print(1); // calls AW::print(int)
print(3.1); // calls Primer::print(double)
return 0;
}
全局作用域中 print 函数的重载集合包含函数 print(int)、print(double)和 print(long double),即使这些函数原来在不同的命名空间中声明,它们都
是为 main 中函数调用考虑的重载集合的组成部分。
● 多重继承
大多数应用程序使用单个基类的公用继承,但是,在某些情况下,单继承是不够用的,因为可能无法为问题域建模,或者会对模型带来不必要的复杂性。
在这些情况下,多重继承可以更直接地为应用程序建模。多重继承是从多于一个直接基类派生类的能力,多重继承的派生类继承其所有父类的属性。尽管概念简
单,缠绕多个基类的细节可能会带来错综复杂的设计问题或实现问题。
class Panda : public Bear, public Endangered {
};
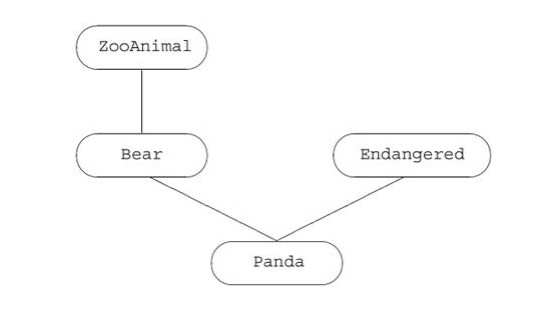
派生类构造函数初始化所有基类:
构造派生类型的对象包括构造和初始化宾所有基类子对象。像继承单个基类的情况一样,派生类的构造函数可以在构造函数初始化式中给零个或多个基类传递值:
Panda::Panda(std::string name, bool onExhibit)
: Bear(name, onExhibit, “Panda”),
Endangered(Endangered::critical) { }
构造的次序
构造函数初始化式只能控制用于初始化基类的值,不能控制基类的构造次序。基类构造函数按照基类构造函数在类派生列表中的出现次序调用。 对 Panda 而言,
基类初始化的次序是:
1. ZooAnimal,从 Panda 的直接基类 Bear 沿层次向上的最终基类。
2. Bear,第一个直接基类。
3. Endangered,第二个直接基类,它本身没有基类。
4. Panda,初始化 Panda 本身的成员,然后运行它的构造函数的函数体。
构造函数调用次序既不受构造函数初始化列表中出现的基类的影响,也不受基类在构造函数初始化列表中的出现次序的影响。
总是按构造函数运行的逆序调用析构函数。在我们的例子中,调用析构函数的次序是 ~Panda, ~Endangered, ~Bear, ~ZooAnimal。
● 虚继承
每个 IO 库类都继承了一个共同的抽象基类, 那个抽象基类管理流的条件状态并保存流所读写的缓冲区。istream 和 ostream 类直接继承这个公共基类,库定
义了另一个名为 iostream 的类,它同时继承 istream 和 ostream,iostream类既可以对流进行读又可以对流进行写。IO 继承层次的简化版本如图 17.3 所示。
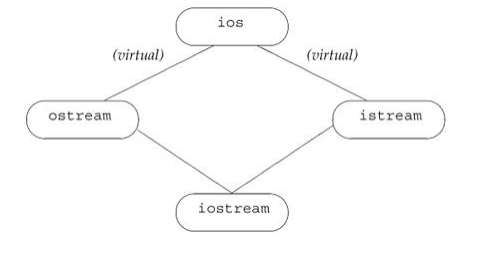
像我们知道的那个,多重继承的类从它的每个父类继承状态和动作,如果 IO 类型使用常规继承,则每个 iostream 对象可能包含两个 ios 子对象:一个包含在它的 istream 子对象中,另一个包含在它的 ostream 子对象中,从设计角度讲,这个实现正是错误的:iostream 类想要对单个缓冲区进行读和写,它希望跨越输入和输出操作符共享条件状态。如果有两个单独的 ios 对象,这种共享是不可能的。
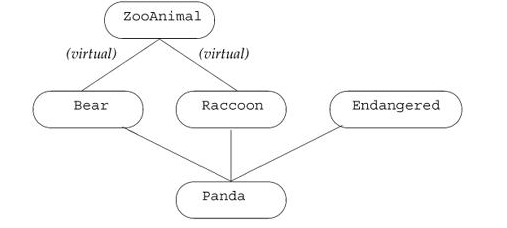
在 C++ 中,通过使用虚继承解决这类问题。虚继承是一种机制,类通过虚继承指出它希望共享其虚基类的状态。在虚继承下,对给定虚基类,无论该类在派生层次中作为虚基类出现多少次,只继承一个共享的基类子对象。共享的基类子对象称为虚基类。
iostream和ostream类对他们的基类进行虚继承。通过使基类称为虚基类,istream和ostream指定,如果其他类(iostream)同时继承他们两个,则派生类中只出现他们的公共基类的一个副本。
class istream : public virtual ios{};
class istream : virtual public ios{};
例如,下面的声明使 ZooAnimal 类成为 Bear 类和 Raccoon 类的虚基类:
// the order of the keywords public and virtual is not significant
class Raccoon : public virtual ZooAnimal { };
class Bear : virtual public ZooAnimal { };
BY:AloneMonkey